关于“Why React”,在我开始了解React的时候,就开始思考这个问题;然后,我开始学习它的用法,尝试着写一个自己的“Hello World”;到了后来,我有幸接触到react体系的真正项目,不断体会和实践着项目的每一个功能的实现;渐渐地,自己有了“Why React?”的体会和看法。现在,是时候总结一下我的收获和体会了。
关于回答“Why React?”,我不想用几句话做出直接的回答,因为这种解释不能完整总结我对前端的整体认识。同时,我的本意也不是要说明我们为什么用React而不用Vue。对于目前业界争论不休的AngularJS, ReactJS, VueJS到底哪个好,存在即有道理,我不做任何回答,而是更偏向于探索“为什么React成为一个流行的框架”。所以,我决定把“Why React?”的回答融合到整篇文章中,分成几个部分阐述我对前端发展的理解和React的出现的意义。
前端的变化和趋势
从上个世纪80年代末期第一个浏览器软件面世开始,Web时代逐渐到来。回顾Web前端的演变过程,大致可以分为以下几个阶段:
- 信息的展示与发布
- RIA的崛起
- SPA takes off
- 端上开花
信息的展示与发布
早期的Web主要是为这个需求设计的。从Http协议到HTML,目的是能够让浏览器获得需要的内容并显示给浏览者。这个时期的Web页面主要以信息展示为主,它提供了文字、图片、声音以及影像等信息类型的支持,浏览者通过这些材料获得有用的数据价值。这个阶段还没有出现Web前端的概念,前端只是网站系统的一部分,前端的职责也是非常明确:即信息的展示。于此同时,业界涌现出的了众多技术体系提供支持,例如:PHP,JSP,ASP等。
RIA的崛起
随着时代变迁,Web2.0到来。它与Web1.0的时代有着本质的区别——即信息的浏览者也是信息的提供者,也是在这个时代,“用户为中心”产品思路开始涌现。这时,Web的界面从信息展示逐渐向信息提供的需求转变,前端的体验开始成为关注的焦点。也正是在这个大环境下,RIA的概念被提出。(RIA: Rich Internet Applications, 富互联网应用)RIA要求Web的界面表现力更加丰富,反应更迅速,有更加良好的交互能力。从而带来的要求就是界面的变化更频繁,更多的异步通信和数据交互,更快的响应速度。
这时,各种博客系统、微博等社交平台纷纷出现,基于B/S架构的SaaS模式软件被提出并广泛应用,将Web推向一个新的高度。这时,曾经只是小打小闹的JavaScript被越来越多的人关注,ECMAScript标准也对应不断的修订和完善,业界也涌现出了更多的库和框架,例如著名的jQuery,YUI前端库,BootStrap、ExtJS等UI组件库。前端的工作内容逐渐变的繁琐和庞大,它不得不从整个Web开发体系中独立出来,专门成立团队进行维护,制定工程化的思路。
SPA takes off
在说SPA(Single Page Application,单页面应用)之前,有一个重要的节点,就是智能手机的普及。随着手机逐渐成为人们上网的主要入口,移动端的Web越来越受到人们的重视。在智能手机普及的早期,app呈现爆炸式增长,一时间涌现出了各式各样的手机app。app在手机上虽然很流畅,可以做的功能也很多,但是仍然存在以下不足:
- 更新速度慢。不管安卓还是ios,app的更新都依赖审核和更新发版,无法做到快速迭代。
- 不同平台不同技术体系。老生常谈,相同的需求至少要分成安卓和ios两个版本,更不要提windows和黑莓这样的非主流系统。
- 拓展性差。由于app受到发版限制,一些实时变化和快速更新的功能在app中存在严重短板。例如电商平台上的促销活动,这类需求特点就是时间短,频繁更换。
鉴于app以上的短板,人们从很早就把方案放到了Web上。在app上开辟一个WebView,里面的内容和交互就自然交给Web来渲染。它可以通过网络请求,直接将Web渲染的结果展示出来。这种方式有效的解决了app的短板,用Web的高度灵活和实时数据来弥补app的发布、兼容和展示上的不足,这也是Hybrid的核心思想。所谓SPA就是要在一个页面上,完成众多交互(甚至页面)的应用,让它能够像一个真正的app模块(甚至app)那样完成所有交互和功能。
需求上的变化,自然也会推动技术上的变革。首先是H5标准落地,然后是ES6的如期而至,各类兼容和开发工具应运而生。功能上的增加,也使得设计模式的思想从后端搬到了前端。同时针对前端的特点,社区也涌现出MVP、MVVM等不同于传统MVC的架构与思想。
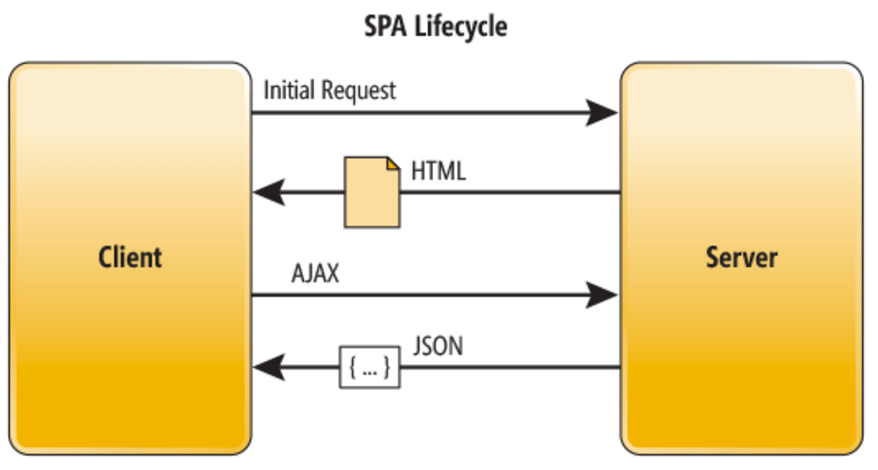
端上开花
纵观人们获取信息的途径,从最早的报纸期刊,到后来的电视,再到电脑与浏览器,再到现在的手机和PAD, 信息的更新传播速度越来越快,展示的载体也越来越多。网络的不断升级与提速,手机的普及,使得浏览器再也不是上网的唯一入口,端的概念逐渐成为发展重心。无论是手机的app,还是电脑上的浏览器,都被抽象成为端。PC端、无线端、pad端、电视端等等,都是信息展示的终端,他们都逐渐被划分为“大前端”这个广义的定义中。与之对应的数据加工和检索,都被聚合到业务处理的下层,他们开始只关注数据和业务本身,不再关注端上的显示逻辑。这种逐渐清晰的分工是互联网快速发展、终端种类变得丰富的大环境下总结出的最佳实践。前端负责适配终端和展示,后端负责数据和业务的处理,中间的链接依靠网络请求和一个固定的数据格式。
后端在这种分离的模式中,得以专注于数据与业务处理,不断抽象和深入,渐渐发展成为大数据和云计算平台,力求通过自身的技术沉淀和服务质量,提供行业解决方案。返观前端,在改进数据变化与展示的同时,兼容性依然是自身不断摸索的和发展的重要的目标。当然,这里指的兼容性,已经不再是以前IE6 hack那么简单,目前亟待解决和不断探索的目标是:
- 各类终端要有尽可能一致的显示效果。
- 各类终端要尽可能提高显示效率、显示性能和用户体验。
- 实现上面两点的时候,开发成本尽可能低。最好一套代码自动适应各端。
这就是前端发展到当下,社区正在不断尝试和业界不断推陈出新的主要目标。安卓、IOS是目前主流的手机平台;传统PC凭借大屏幕、高性能仍在在某些场景下发挥出巨大优势;针对这些终端,前端发展到目前,还没有一个完善和健全的工程方法和解决方案,做到快速、高效、低成本的开发。
当然,目前业界已经有很多新概念和新思路涌现。微信小程序和Weex虽然在机制上存在不同,但是本质都是希望通过发布自己的规范,让开发者写出的代码能够自动不同类型的手机上转化成对应native的原生组件,达到和native app一样的性能和交互体验。同时,在移动端浏览器或WebView上,Weex可以自动降级为H5,保证界面和功能正常。Google在2017年伊始,提出了PWA(Progressive Web App),它的目标是利用浏览器的能力,达到类似App一样的用户体验和效果,让浏览器打开的网址像APP一样运行在手机上。这两种不同方向上的技术尝试,目标是一致的,就是提供一种方案,让一套代码能在不同手机和终端上,达到相同的效果和流畅的体验。
所以我相信Web前端未来的发展,一定是端上开花的过程。它现在还是含苞待放,安卓、IOS、手机H5、PC浏览器目前还是需要工程师针对不同平台单独开发不同的项目,相信在不久的将来,前端定会出现一个成熟的可以各端适配的工程方案。
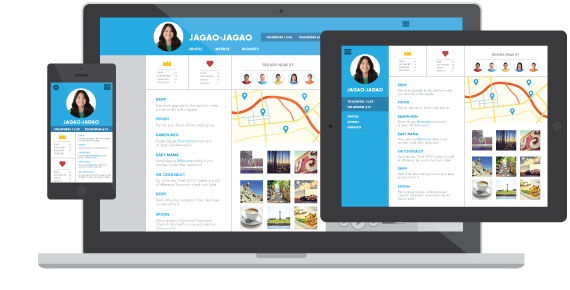
被动式模块和响应式模块
在开发Web前端页面时,我们会将每个功能划分成小的单元,每个单元有相对独立和具体的小功能,这些单元就是模块。模块化开发就是将这些小的逻辑单元分开,彼此间尽可能的独立开发和维护,并且通过约定好的格式或框架相互组合起来。
我们假设一个最简单的例子,一个博客的点赞数模块。博客在打开之后,异步请求该文章被点赞的次数,当后端返回一个指定数字之后,Controller接收到这个数字,获取需要显示的模块对应的位置,并将数字更新上去。它大致的流程是:

图中的点赞数模块,应该是View中的一个显示模块。当处理数据的模块得到数据之后,需要通过类似于jQuery、Kissy那样的选择器(或通过框架的钩子方法)来找到点赞模块的具体DOM,然后将数据更新上去。例如这样:
Loader.onLoad((data) => {
let node = $('#goodContainer');
node.html(data);
});
上面我们可以看到,goodContainer这个模块并不知道什么时候更新,也不知道具体怎么更新,它完全是被动的被修改。所以这样架构和设计的模块,就是被动式模块。被动式模块对Controller有很强的依赖,它不能独立存在,也不能随便撤掉(想想Controller中有大量钩子函数),同时,对应的Controller部分也变得十分臃肿,Controller必须彻底了解模块的每一个显示细节,并且,需要大量的UI相关的修改方法和语句。不难想象,在很多前端模块中,充斥着大量诸如addClass(), removeClass()等和UI展示逻辑相关的代码。也正是这种需要的大量存在,造就了jQuery这样成熟的前端工具库。
再来说说另一个完全相反的思路。当处理数据的模块得到数据之后,通知点赞模块,点赞模块主动获取点赞的数字,然后自己更新了点赞数。这种流程可以总结为:
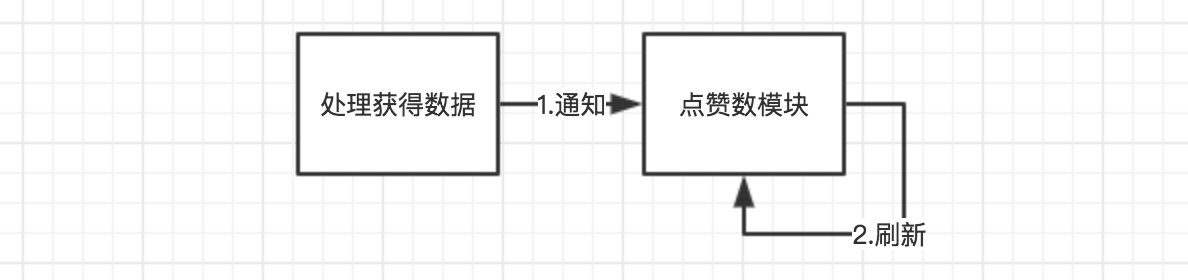
在获得数据的模块得到数据之后,通过订阅模式(也可以是事件),通知所有订阅了该数据的模块。所有依赖点赞数的模块会自动load数据更新,并自己刷新,这种模块就是响应式模块。上面这个过程类似于:
// loader
Loader.onLoad((data) => {
Global.dispatchEvent('update', data);
});
// UI components
GoodContainer.addEventListener('update', (data) => {
this.refresh(data);
})
响应式模块可以自动更新自己的状态,这样切断了数据接收和数据显示之间的代码耦合。他们之间通过事件或者订阅的方式连接。这样的设计思路,可以使模块独立出来,外部调用者不需要知道模块的具体显示细节,只需要关注订阅的关系即可,从而实现了模块的可插拔,模块之间真正的独立。
UI的命令式编程和声明式编程
如果形象的描述命令式编程和声明式编程的区别,我想可以用下面这个例子来阐述:
在显示一个人的体态外观特征的时候,我们用命令式的方式写出伪代码,它大致的思路是:
let p = new Person();
p.set('头发颜色', 'black');
p.set('身高', 180);
p.set('体重', 75);
p.set('年龄', 30);
相同地用声明式的方式的思路是这样的:
let p = new Person();
let charactor = {
'头发颜色': 'black',
'身高': 180,
'体重': 75,
'年龄': 30
};
p.refresh(charactor);
从这个例子和对比中,我们就可以清晰的看出这两种不同思路的特点。命令式编程关注每一个步骤的具体内容,它在组件中就需要安排好每一个显示的细节,对组件状态的每一个改变都要事必躬亲,明确每一个改变的步骤。而声明式编程的思路完全不同,它关注数据发生变化,并将变化的内容告诉组件,组件的改变自己并不关心,将真正变化的细节全部交给组件自己更新状态。
命令式编程是Web前端的常规开发思路,它在开发初期,接到功能需求时就可以进行分析,当数据变化时自己都需要做什么,然后就按照todo-list一步一步将步骤写下来。这样做的好处就是:
- 需求转化成代码的速度快;
- 数据变更之后UI变化的效率也高。
但同时也存在比较明显的短板:
- 当功能和模块增加时,代码就变得异常臃肿;
- 当存在大量异步更新时,UI的变更就会陷入很深的异步嵌套中;
- 对作者依赖性很强,当换一个人维护它时,读懂每一步的操作就变成了噩梦。
声明式编程的思路很早就出现了,它的核心思路就是将UI的样子像描述HTML那样描述出来,每次变更只需要修改模块依赖的数据,并通知模块自己重新刷新即可。它可以有效的解决命令式编程的短板,让每个模块解耦、相互独立,可以分开维护,拓展性强。但是,这种思路直到近几年才被广泛使用,究其原因主要有以下几点:
- 描述状态的方法过于复杂。
- 更新状态的方式效率太低,性能开销较大。
下面对上面两点做一下解释。我们在上文中说,声明式编程希望将UI的外观描述出来。能做到这一点其实不简单:如果采用模板的方式来描述,虽然可以在编写模板时清晰方便的写出所有描述逻辑,但是它在变化时,引起的效率和性能开销太大。因为更新模板会导致模板根节点以下的所有节点全部刷新,这对浏览器带来的开销很大(试想如果要更新某个大列表中某一项的某一个字体的颜色,需要把整个列表都重新刷新一遍),并且会带来很多事件的丢失;如果采用自定义的数据结构来描述,虽然在更新时,我们可以通过自己的算法来决定哪个dom变化,但是在编写这个数据结构时,是非常难以理解和维护的。
在声明式编程发展的道路上,React的JSX给这个思路的开发和实现注入了新鲜的血液。首先JSX是一个语法糖,它会将JSX的语法进行解释和转化,创建出React组件对象,这样保证了React可以用自己的Diff算法进行高效的更新DOM。第二,JSX采用了和HTML相似的语法,并且支持所有HTML规范中的标签,使得它在使用上入门简单,并且便于阅读和维护。JSX的出现,使得声明式编程快速的普及,这种思路和方式纷纷被各大框架采用。Vue在2.0版本中也引入了JSX,足以说明这个趋势和尝试是非常成功的。
MV*
MVC
提起MVC,很多人认为MVC是一种框架,而我认为,MVC是一种思想。我们把一个网站的数据、展示、和两者的链接分别独立,就构成了Model,View和Controller。MVC的思想最早出现在服务端,在传统的Web服务中,View是前端界面,由服务端负责Model和Controller的实现。随着前端的需求变得复杂,前端独立出来,自身也引用了MVC这种思想组织自己的结构。在前端的MVC功能划分,大致可以总结为:
- Model: 负责存储和业务数据,是一个页面功能的核心数据的抽象。
- View: 负责展示UI,将渲染的UI呈现给用户,并监听用户的各类操作事件。
- Controller: 负责链接Model和View。响应View发出的各类事件,修改Model,再将修改后的结果重新返回给View重新渲染。
一种典型MVC架构的前端页面场景可以总结为下图:

从上图中可以看出MVC架构的前端页面具有以下几个特点:
- Controller负责监听事件、修改Model、修改View等
- Model不需要了解View的细节
- View不知道何时会更新自己,也不知道自己如何更新
由此可以看出,MVC架构的前端页面存在以下短板:
- Controller中包含大量的事件监听,处理业务逻辑,修改View显示逻辑。
- View严重依赖Controller,它不知道自己所需要的数据内容,无法单独分离和解耦,也不能单独的维护。
- 当页面的模块增多时,Controller会变得非常庞大。随着模块和彼此间的交集变多时,Controller将变得无法维护。
MVVM
虽然MVC在实际的应用中有着大量的实践,但是其短板非常明显,在庞大的项目中,给Controller减负势在必行,因此,MVVM的模式出现了。
MVVM是一种MVC的改进,Controller变成了ViewModel。它在主要做了以下的改进:
- View由被动式模块转变为响应式模块,它自定了一套用于显示的数据,成为无状态View。
- View与model之间进行了绑定,即View中的表单等内容发生变化,会自动更新Model,反之亦然。
- ViewModel负责修改View的显示数据,接收到Model的变化之后,负责分发事件,通知所有View进行变更。
它的典型场景如下:

可以看出,MVVM思想有效的减轻了中间处理层ViewModel的负担,VM不需要关注View视图的显示细节,所有的变更都是通过订阅模式分发出去,各个组件和模块根据数据自己进行更新。这样做有效的将View解耦出来,更加便于模块的组合和独立维护。
双向绑定和单向绑定
在MVVM的结构中,我们提到了数据绑定,所谓数据绑定,就是UI上的显示数据与Model中的某个数据存在联系,其中一个变化,另外一个会自动变化。如下图:
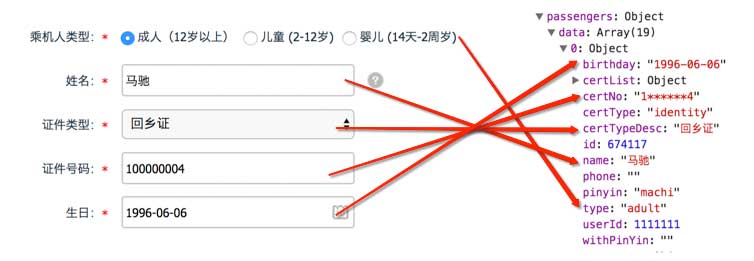
图中的乘机人表单中,需要用户填写相关的信息。在数据绑定之后,当用户输入姓名时,Model中的name会自动更新为用户输入的内容。
实现数据绑定的方法,究其本质是在Controller(或Presenter,或ViewModel)中给上面这些表单绑定change事件。用户输入或改变选项时,通过事件回调,将Model中对应的数据更改。这就实现了UI到Model的绑定,反之亦然。
双向绑定
双向数据绑定就是UI与Model之间双向的绑定,即:UI变化时,Model数据会跟随变化;同时Model数据变化时,也会自动更新UI变化。双向绑定特别适用于存在大量表单的需求中,用户对表单每一项的改动,都会自动更新到Model的数据中,这样非常便于数据的集中处理和提交。
单向绑定和Flux
This means that one change (a user input or API response) can affect the state of an application in many places in the code — for example, two-way data binding. That can be hard to maintain and debug. 原文地址
Redux的作者在回答“How is it different from MVC and Flux?”的问题时回答了双向绑定的不足,双向绑定不利于代码的维护。究其原意,是因为双向绑定让UI和数据相互作用,当UI引起变化时,数据跟随变化,但是数据的变化又重新作用UI变化,这就造成了不小的麻烦。例如:当我们希望在一个界面上同时展示未读信息列表与未读信息的总数目的时候,一旦我们将某个未读信息标识为已读,会引起控制已读信息、未读信息、未读信息总数目等等一系列模型的更新,如果我们把这些组件分别放在几个不同的MV*中的时候,就会导致不可预测的结果和性能的损耗。
单向数据绑定就是去掉双向中的其中一个方向的绑定,让变化按照一个方向进行传递,这样有效的降低了双向变化造成的性能开销。由于UI的变化不能包含所有的页面数据变化case,所以,我们一般会保留Model对UI的绑定。
Flux
Flux是Unidirectional Architecture中最出名的一个,光是它的实现就有十多种,其中应用最广泛的是Facebook官方的实现。Flux是一个典型的单向数据流架构,它主要由以下几部分组成:
- Stores,负责存放Model数据。
- View,UI组件。
- Actions,用户通过操作View而发出的各类事件。
- Dispatchers,它来负责分发用户触发的Action。
它的大致流程是:

从上面的流程图中,我们可以大致看出Flux架构的基本思路。它的特点大体可以总结为:
- 变化的起源是View发出的action。让View发出action的动作,可能是用户的操作,也可能是View自己初始化行为。
- 所有事件都统一经过Dispatcher,由Dispatcher统一进行处理。Store的变化只能有Dispatcher修改。
- View的变化只受Stores影响。
Flux是单向数据流思想的重要的实现,它体现出了一个比较核心的思想:数据决定UI。这种方式可以更高效的处理当数据发生变化时,UI该如何变化的问题。同时单向数据绑定确保程序在更新UI时不需要花费额外的精力来判断哪些UI是变化源头,大大提升了显示效率。这种架构可以被各个组件单独使用,并在多个组件共存时有效的减少之间的耦合。
关于单向数据流和双向数据流在性能上到底孰优孰略目前尚无定论,不少双向绑定的框架在性能上做了诸多优化,性能已经到了很好的地步。同时,他们各自都在工程中有很多实践,稳定性和可维护性都各有特点。不过,我认为单向绑定的思想在前端工程化中有一个重要的优势:它严格限制了数据变化的方向,约束了开发者的代码。所有基于这种思路开发的程序,都是按照同样一个数据方向进行处理的,这样有效避免了每个人因为想法不同造成的程序风格千差万别,大大降低了阅读和维护代码的成本。
Why React?
是时候回到正题总结一下了,我在前面详细的说明我对前端的演变、被动式和响应式组件、命令式和声明式编程和MVx的个人理解和看法,这些的变化和区别都是在说明一个问题:前端正在不断改进数据变化引起界面变化的方法。这也是我理解的为什么React会出现和流行,并且在一年之内获得了6万多star的原因。它在前端各个发展领域上给出了一个革命式的新方式。
JSX
首先,React带来了JSX。JSX的书写方式更加近似于HTML,这使得它的入门门槛大大降低,它可以从代码层面方便地实现组件的描述和嵌套关系,让UI组件和模块真正的可以像HTML标签那样随意组合和插拔嵌套;同时,JSX是一个语法糖,它的背后是一套自己的解释逻辑,JSX被解析成一个React自己的数据结构,从而让框架的数据结构对开发者相对透明;此外,React使用JSX真正的实现了组件JS化。回想我们在开发传统的UI组件时,UI和逻辑永远都是分离的。UI是HTML,逻辑是JS,两者永远不能合在一起,UI需要给逻辑提供钩子,逻辑需要通过钩子找到UI。JSX的出现,真正实现了在JS中描述组件的UI,使得模块化开发达到了新的高度。借助React的组件化方式,我们不再需要DOM选择器,也不用关注组件和逻辑连接的问题。
Redux
Redux是Flux思想的一种实现,它的作用和Flux相同,不同的地方在于:
- Redux只有一个store。Flux中允许有多个store对应不同模块的数据存储,而redux则将多个store合并成一个完整的store。
- Redux取消了Dispatcher,而是使用reducer来进行事件的处理。reducer是一个纯函数,它根据不同的action,推导出新的state。redux允许存在多个reducer,让每个reducer负责某一个具体的功能,但是他们需要通过combineReducers合并成一个根reducer。
React和Redux的结合,可以完成各类前端数据变化的场景。所有UI上的事件都通过reducer返回一个全新的state集合,这个state集合可以直接让react根据生命周期更新界面。它让整个页面的组件无状态化的同时,还让所有用户操作变得可以追踪调试。在开发测试中,只要能够得到所有状态,就可以模拟任意的一种操作,为测试UI提供了一个重要的手段。
Virtual-DOM & Diff算法
第三,React引入了Virtual-DOM的机制。通过JSX转化成的React对象就是Virtual-DOM的来源。我们知道在单向数据流的思想中,当数据变化后会触发视图进行变化,而如果通过描述性语言来更新所有的DOM(innerHTML)会带来巨大的性能开销。所以,React引入了Virtual-DOM来优化这个过程,毕竟,浏览器在处理JS的速度和效率要远远大于处理DOM(判定DOM的变化效率极低,更不用说DOM变化带来的重排和重绘)。这个对比变化的JS对象就是Virtual-DOM,而对比Virtual-DOM是否需要更新的算法就是Diff算法。React就是通过Diff算法计算出要更新的Virtual-DOM,然后再根据Virtual-DOM找到真正需要改变的真实DOM,这样大大提高了页面的更新效率。得益于这种方式,React+Redux很好的实现了单向数据流、JS组件化、描述性UI等诸多特性。
React Native
在React体系中,我们不难发现在一个Web页面上,从用户操作到数据处理到页面刷新,真正需要浏览器变更UI的时候,就是render的过程,它对数据的流转和处理没有任何强关联。因此,如果我们将这套体系直接搬到手机app上时,实际只需要修改render这部分就可以了,这就是React Native出现的原因。RN的出现给多端适配提出了一个新的思路和方式。由于在我实际的项目中,还没有使用过RN,它还有很多需要完善的地方,所以这里就不多说了。
什么项目适合React体系?
终于可以解答这个问题了,我个人认为:UI依赖数据变化而变化,这样的UI越多,就越适合React 几点补充:
- 必须是UI依赖数据,而不是数据来源于UI。例如我们为了显示一个人在地图上的位置,所以我们有了x和y,这个(x, y)就是UI依赖的数据,UI需要根据这个(x,y)来显示。反例是:我们需要做一个点在容器中运动,我们为了画出这个点而引出的(x, y),虽然这个场景的UI也是靠(x, y)进行渲染的,但不是我们需要的数据模型。
- 变化的内容是有限的,可以追溯的,且每次变化是稳定的。
例如:复杂的表单填写页面。页面需要大量的input让用户填写,同时,页面上需要大量实时校验数据的功能。我们可以很容易的创建一个store来保存所有需要提交的数据,通过render来描述每个input对应哪个字段,所有的输入操作都通过action分发,校验在reducer返回结果之后给出,再通过render更新结果。整个体系不需要你使用钩子找到对应的dom,也不需要你逐个绑定事件,高效的Diff可以让你无需关注联动校验需要在哪里提示什么错误。
Last but not least
总结到这里,我感觉在“Why React”这个问题的阐述上,已经不是简单的“为什么要用React”了,它更加趋向于探讨“为什么React会流行”。纵观前端的发展和演变,从早期我们使用的jQuery,YUI,Kissy,到后来我们引入MVC和框架,再到后面探索Weex、RN,使用小程序,都是在追寻这三个核心目标:1.如何处理变化?2.如何做到兼容?3.如何提升体验?在这三个目标上,React带来了很多新的特性和新的尝试,也正是它的出现,给前端开发注入了很多新的有价值的思路。所以,无论Vue也好,React也好,Angular也好,还是XXX也好,争论到底哪家强并没有什么意义,重要的是,这些框架在相互借鉴相互完善下,为前端的发展带来新的实践方案,为用户体验带来新的改善。